Explainable neuromorphic computing
Ref.
Visual explanations from spiking neural networks using inter‑spike intervals
Main Contents
本文提出脉冲激活图(Spike Activation Map, SAM), 无需反向传播或依赖梯度即可获得“视觉解释”. 这与Grad-CAM不同(通过反向传播计算梯度来量化浅层到深层神经元对目标类别预测的贡献)
我们利用了这样一种生物学观察:短脉冲间隔(ISI)的脉冲在神经系统中包含更多信息,因为这些脉冲更可能通过提高神经元的膜电位来引发突触后脉冲。针对SNN所做出的预测,SAM为网络中的每个神经元计算一个神经元贡献分数(Neuronal Contribution Score, NCS)。NCS分数定义为先前脉冲的时间脉冲贡献分数(Temporal Spike Contribution Score, TSCS)的总和,并使用指数核函数计算。
对于在短时间窗口内多次脉冲的神经元,TSCS较高;相反,对于在较长时间内发放脉冲的神经元,TSCS较低。
Results Comparison
SN ...
ANN2SNN Principles
Ref.
Zihan Huang, Xinyu Shi, Zecheng Hao, Tong Bu, Jianhao Ding, Zhaofei Yu, and Tiejun Huang. 2024. Towards High-performance Spiking Transformers from ANN to SNN Conversion. In Proceedings of the 32nd ACM International Conference on Multimedia (MM '24). Association for Computing Machinery, New York, NY, USA, 10688–10697. https://doi.org/10.1145/3664647.3680620

计算神经科学中的高效编码机制探究
Refs
Energy-Efficient Neuronal Computation via Quantal Synaptic Failures, William B. Levy and Robert A. Baxter; The Journal of Neuroscience, June 1, 2002, 22(11)
Another contribution by synaptic failures to energy e cient processing by neurons, Joanna Tyrcha;∗, William B. Levy; Neurocomputing 58–60 (2004) 59–66
Quantal Synaptic Failures
主要参考Ref.1.
Prior Knowledge 1: Basic Mathematical Modeling of Neurons, a information theory perspective.
🍭Perspective 1: 树突体求和 等价于 香农信道。
随机的突触信号传递过程被视作树突体求 ...
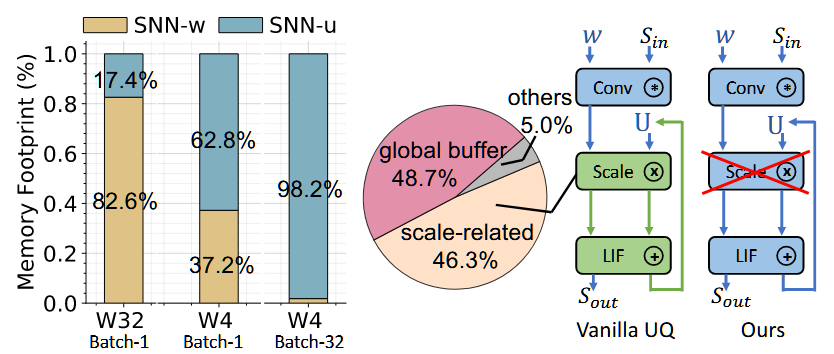
毕业设计(三)文献调研:MINT-SNN
Abstract
本文创新点:
将存储密集型的膜电位量化到了极低2bit精度。
在权重和膜电位数据的均匀量化中共享缩放因子。
效果:2-bit的VGG-SNN-16:90.6%(CIFAR10),memory footprint减少93.8%,computational energy减少90%。
Introduction

Vivado AXI Datamover
参考资料
Xilinx User Guide: pg022_axi_datamover
AXI Datamover IP 概述
(这次主播决定从官方手册出发,仔细研读手册内容从而达到能够独立开发该IP的目的。)
AXI DataMover和AXI DMA的功能非常相似,都是为在AXI4 memory-mapped(AXI4存储器映射)和AXI4-Stream domains(AXI4流数据)之间提供高吞吐的数据传输。该IP核的MM2S(即Memory-map to Stream)和S2MM(即Stream to Memory-map)通道独立运作,整体通信是全双工的。
**内存映射(Memory Mapping)**是一种将文件内容映射到进程的虚拟地址空间的技术。在这种机制下,文件可以被视为内存的一部分,从而允许程序直接对这部分内存进行读写操作,而无需传统的文件 I/O 调用。这种方法不仅简化了文件操作,还提高了处理效率。支持4KB的边界保护以及自动拆解太长的burst
AXI Stream: 一种高速流传输的AXI总线协议,详情见ARM官方手册:AMBA AXI-Strea ...
Vivado AXI-DMA开发
0. 参考资料
Xilinx PG021 AXI IP手册
AXI DMA示例程序:axidma: Vitis Drivers API Documentation
1. AXI DMA概述
AXI DMA即利用AXI接口的Direct Memory Access(直接内存访问),为内存和AXI-Stream流的外设之间提供高带宽内存访问。其功能框图如下图所示:
其中有两类访存数据的接口:Memory Map和Stream。Memory Map(存储映射)的接口是负责读取存储空间(如DDR)的数据(本质是AXI4-Full接口),经过DataMover之后转换成AXI Stream数据(或主或从)。AXI4 Control Strea、AXI4 Memory Map Write/Read 和 AXI4 Stream是Scatter/Gather功能下的接口。AXI-Lite为AXI总线的配置接口。
2. AXI DMA时钟接口介绍
本IP Core共有四个时钟输入:
Signal Ports
Description
m_axi_mm2s_aclk
用于MM2S接口
...

天府人工智能会议一些好玩的研究
1. Drivers of Progress in AI and Silicon Valley’s Al Innovation by Piero Scaruffi
人工智能发展的驱动力是 1. 硬件;2. 数据集;3. 开源;4. 国际合作
2. 通用大模型赋能新质生产力 by 乔宇
上海AI Lab 书生系列大模型:intern-ai
3. 算力网络研究思考 by 张宏科
4. Pangu大模型赋能新质生产力
5. 面向是视觉识别的长尾分布数据学习, Yiu-ming Cheung, 香港浸会大学
6. 具身智能:从模拟到现实, 蒋树强, 中科院计算所
7.当进化计算遇到大语言模型,Kay Chen Tan, 香港理工大学
8. 具身智能:从数字空间走向物理世界,林琼,PCL/中山大学
9. 表情特征研究
10. 模拟生物智能的神经形态 ...
如何写好一篇学术论文
论文写作之三剑客
1. 写作前准备下面三个问题
想好解决什么问题
为了解决这个问题,我提出了什么方法/方案
实验结果是否能证明方案可行
2. 写作中切记
站在巨人的肩膀上,广泛搜集文献并速览
在已有的好的逻辑的文章的基础上进行合理“抄袭”/反写,不照搬照抄,而是学习别人的行文逻辑
注意上下文段落的衔接。完整的一个部分应遵循“一条龙”的逻辑原则(尤其注意每一段的第一句话,最后一句话是否能在逻辑上紧密联系)
Digital VLSI Design (RTL2GDS) Notes I
1. Introduction
学习路线:Design Abstraction->Design Automation(EDA)->Design Re-use(IP);
General Design Approach
Divide and conquer
分解问题
数学建模
合理使用工具链
验证测试
再思考(回到开头)
设计的抽象化
系统级(system level)
寄存器传递层级(RTL,register transfer level)->Verilog/SpinalHDL
门级(gate level)
三极管层级(transistor level)
布局(layout level)
掩膜(mask level)
或者在VLSI的实际设计过程中,分为以下级别:
应用级
算法级
编程语言层
操作系统/虚拟机层
指令集结构层
微架构层
RTL
电路
元件(三极管)
物理定律
EDAs in VLSI
RTL
Verilog
Synthesis
Cadence Genus
Place and route
Candence Innovus
Sta ...

毕业设计(三)文献调研:神经架构搜索与投射
References
Vitis AI手把手教你如何部署自己的模型:Developing a Model, Vitis AI
Vitis AI Manual - Compiling the model
Introduction about NAS
NAS (Network Attached Storage:网络附属存储)按字面简单说就是连接在网络上,具备资料存储功能的装置,因此也称为“网络存储器”。它是一种专用数据存储服务器。它以数据为中心,将存储设备与服务器彻底分离,集中管理数据,从而释放带宽、提高性能、降低总拥有成本、保护投资。其成本远远低于使用服务器存储,而效率却远远高于后者。
这次要聊的NAS概念,算是比较新兴,全称Neural Architecture Search,神经架构搜索。作为自动化机器学习(AutoML)的一个部分,NAS旨在让设计特定任务的神经网络架构变得更加自动化,更加地智能。
机器学习这一个强大的数据处理流水线上,不管是何种算法,绝大部分都贯穿着
💾数据清洗(data cleaning)
⚒️特征加工与选择(feature engineerin ...