EMS-YOLO的魔改记录
EMS-YOLO的工程结构
1 | EMS-YOLO |
其中,models/common.py放了很多YOLO的基本模块定义。让我们来看一看这些模块的功能:
1. 二值量化
1 | class BinaryQuantize(Function): |
功能
前向传播时以零为界输出二值化后的张量,即
反向传播貌似使用了某种代理梯度(surrogate gradient)来计算:
2. SNN-qConv2d(量化二维SNN卷积)
1 |
|
该模块继承经典的nn.Conv2d, 前传过程中将权重标准化,计算量化缩放因子,二值化处理,再送到卷积层中处理。
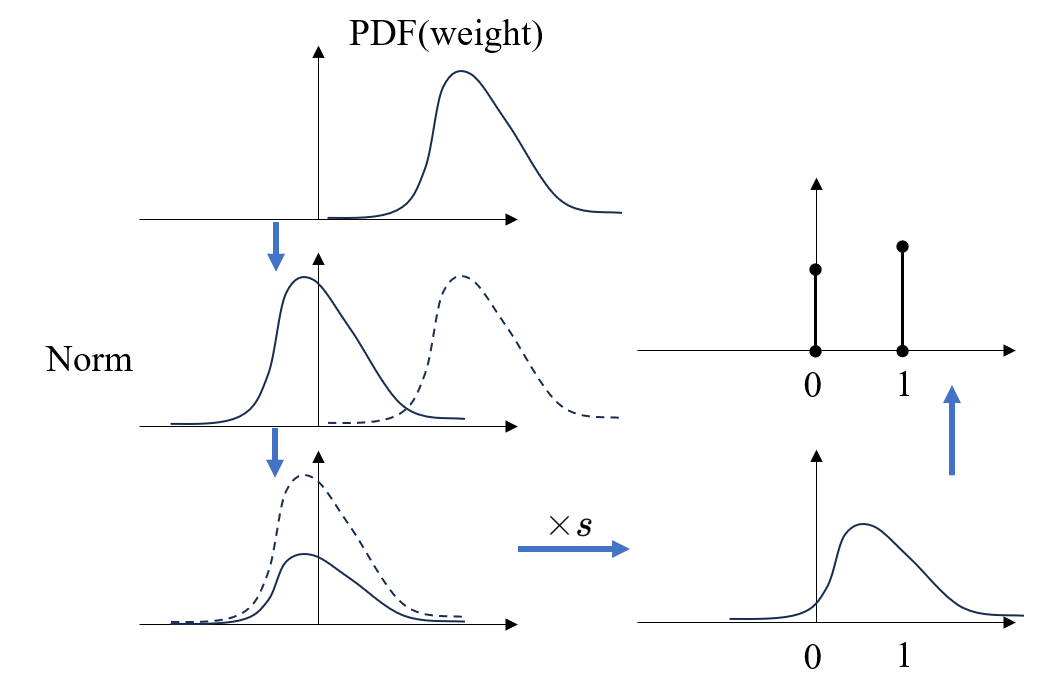
3. 膜电压正负二值(-1,1)量化
1 | def u_q(u, b, alpha): |
step.1 非线性映射到
step.2 截断处理
step.3 量化
4. 放电函数
1 | lens = 0.5 # 0.5 # hyper-parameters of approximate function |
前向传播时输出脉冲(比阈值大的输出1,否则为0),反传过程中梯度近似为放电为1,不放电为0。
5. 自定义的Conv-BN-LIF卷积层
1 | class Conv(nn.Module): |
6. 使用SiLU激活函数的卷积层
1 | class Conv_A(nn.Module): |
7. 不使用激活函数的卷积层
1 | class Conv_1(nn.Module): |
8. 魔改过的BatchNorm层
不同之处在于初始化权重不同.
1 | class batch_norm_2d(nn.Module): |
9. 对输入的每个时间步应用的 MaxPool2d 池化操作
1 | class Pools(nn.Module): |
10. 对输入的每个时间步应用的 ZeroPad2d 填充操作
1 | class zeropad(nn.Module): |
11. 对输入的每个时间步应用的UpSample操作
1 | class Sample(nn.Module): |
12. 逐通道卷积
继承Conv类,设置卷积组数g为输入和输出通道数的最大公约数。
1 | class DWConv(Conv): |
Ultralytics中的Tiny-YOLOv3的Backbone结构
1 |
|
.yaml文件中对于模型的描述如下:
1 | # YOLOv3-tiny backbone |
原始的Tiny-YOLOv3的Backbone中只有Conv、MaxPool2d、ZeroPad2d三种模块,head中有Conv、UpSample和Concat三种模块。而EMS-YOLO的作者们已经为我们改好了带有时间步的各个模块。于是一个大胆的想法油然而生:暴力替换
替换之后的yaml文件如下:
1 | nc: 80 # number of classes |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Eric's Blog Site!
 wechat
wechat- alipay