毕业设计(三)文献调研:神经架构搜索与投射
References
-
Vitis AI手把手教你如何部署自己的模型:Developing a Model, Vitis AI
-
Vitis AI Manual - Compiling the model
Introduction about NAS
NAS (Network Attached Storage:网络附属存储)按字面简单说就是连接在网络上,具备资料存储功能的装置,因此也称为“网络存储器”。它是一种专用数据存储服务器。它以数据为中心,将存储设备与服务器彻底分离,集中管理数据,从而释放带宽、提高性能、降低总拥有成本、保护投资。其成本远远低于使用服务器存储,而效率却远远高于后者。
这次要聊的NAS概念,算是比较新兴,全称Neural Architecture Search,神经架构搜索。作为自动化机器学习(AutoML)的一个部分,NAS旨在让设计特定任务的神经网络架构变得更加自动化,更加地智能。
机器学习这一个强大的数据处理流水线上,不管是何种算法,绝大部分都贯穿着
- 💾
数据清洗(data cleaning) - ⚒️
特征加工与选择(feature engineering and selection)、 - 📉
超参数优化(hyperparameter optimization (HPO))、 - 🔎
神经架构搜索
这四个处理过程。其中,HPO和NAS地根本思想都是最优化问题,从某种特定的优化函数(搜索空间)找到最优解。显然,二者的某些算法实现上是相通/趋同的。但是,二者又有着区别:HPO问题中,一般而言,每一个超参数的取值范围/值域(domain)互不影响。因此,HPO 问题的典型搜索空间是一系列连续和分类维度的乘积空间。(我也读不懂,放出原文:… the typical search space of an HPO problem is the product space of a mix of continuous and categorical dimension.)。相反,NAS问题在于搜索一个最优的神经网络架构,而每一个神经网络都可以被表征为一个有向无环图(directed acyclic graph (DAG)),因此NAS 问题的搜索空间通常是离散的,可以直接表示为图形,也可以表示为条件超参数的层次结构。(依然读不懂,放出原文: the search space of a NAS problem is typically discrete1 and can be represented directly as a graph, or as a hierarchical structure of conditional hyperparameters.)
从2017年ICLR的一篇文章:Neural Architecture Search with Reinforcement Learning, Barret Zoph & Quoc Le起,NAS才被人工智能研究人员重视,并且在这之后的短短5年(2018-2022)共有1000+篇关于NAS的论文发表。NAS的方法从一开始的基于黑盒的(black-box based),发展到盛行的一步法(one-shot)。近些年,研究NAS的方向主要可以划分为两大并驾齐驱的方向:开发更加稳定(robust),置信度更高(reliable)的one-shot方法和发布权威的benchmark,让NAS研究更具可重复性和科学性(NAS-Bench-101)。NAS的应用领域也从一开始的图像特征提取(即分类,classification)任务,拓展到了目标检测(object detection){题外话:xilinx的vitis AI model zoo中的ofa-yolo就是个很好的例子}、语义分割(semantic segmentation)、语音识别(speech recognition)、偏微分方程求解(partial differential equation solving)、蛋白质折叠结构(protein folding)的识别预测、气象预测(weather prediction)、自然语言处理(natural language processing)
Backgrounds and Definitions
NAS的最简洁的表达方式如下图
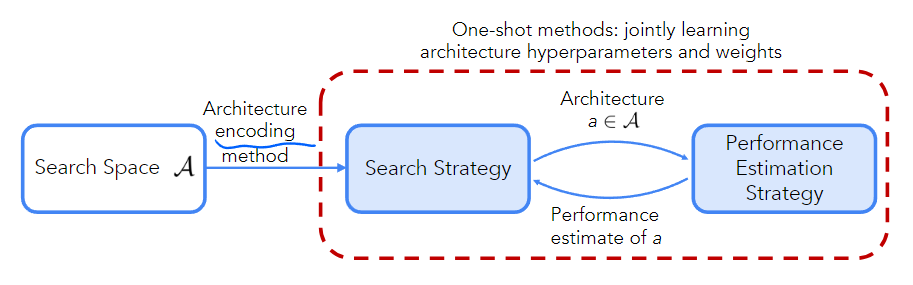
给定一个搜索空间,一组数据集,一条训练数据流,和一个时间开或者计算开销。目标是找到一个开销不大于的网络架构,使用数据集和训练流进行训练能达到最大可能的验证集准确率。用数学公式表述为:
让模型学习如何学习,有点元学习(Meta-Learning)内味了。
三要素:
1. Search Space (搜索空间)
概念:NAS算法允许检测到的所有网络架构的集合。
当然不会让算法暴力搜索 (猴年马月搜完) ,设计时会加上一些被称为domain knowledge的先验知识用来简化搜索。但先验知识加的多了也有弊端,会引入人为偏差(human bias),使得模型搜寻极其新颖的架构变得很困难。
2. Search Strategy (搜索策略)
概念:用于找到高性能的网络架构的优化策略,一般分为两大类:黑箱策略(RL、Bayesian优化、进化/遗传算法)和一步法策略(supernet-/hypernet-based)。
3. Performance Estimation Strategy (性能评估策略)
概念:为避免对模型进行训练而衍生出的快速高效评估模型性能的算法(eg: learning curve extrapolation).
Search Space
选定search space是NAS的第一步,且这个步骤是很明显的任务驱动、依赖SOTA模型的。
Search space也是需要精心设计的,需要在人为偏差(human bias)和搜索有效性(efficiency)之间做权衡。具体而言:如果search space很小,并且包含了很多人为引入的决策,NAS会用很短的时间找到一个高性能的模型。相反,如果search space过大,并且没有太多的先验知识,纯粹靠模型自主构建,那么找到心仪的模型需要很长的时间,但有机会找到一些新的、突破性的模型架构。
1. Terminology (术语)
关于search space中的术语,在此进行介绍。读者们可以结合下图和文字说明,更加深刻地理解每个术语地含义。
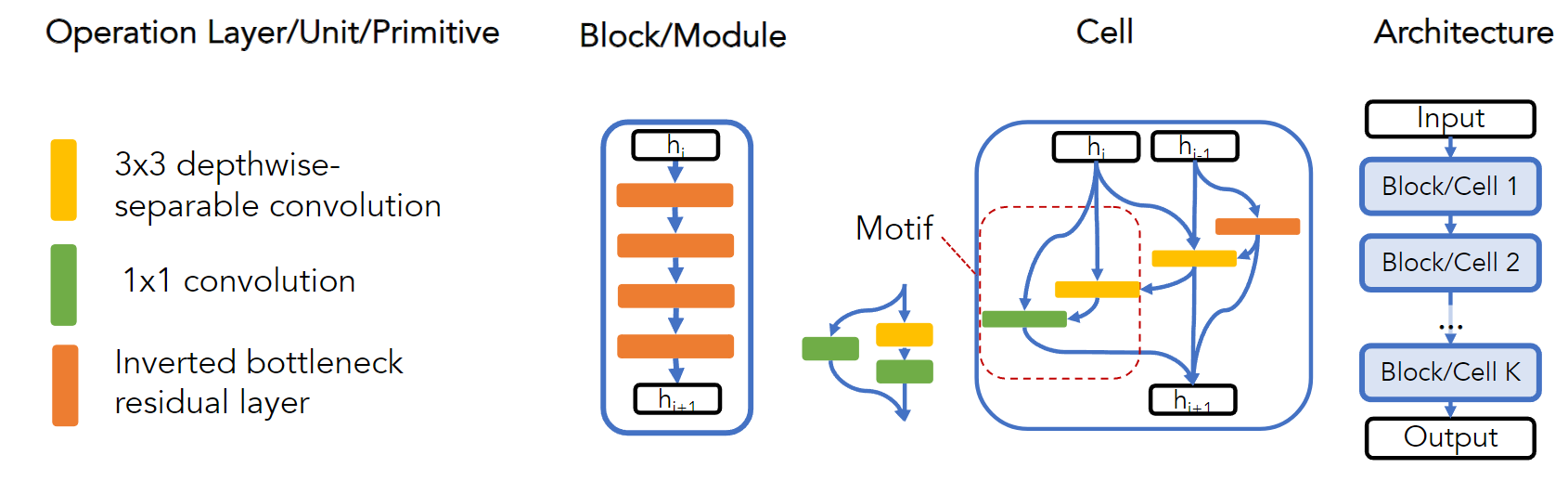
- Operation/Primitive: 基本操作单元,如今的主流NAS算法中,一般都将
ReLU[fixed]-conv 1x1[variable operation]-BatchNorm[fixed]当作一个Operation/Primitive 单元 - Layer: 层,出现在链式结构或者稍大一点的search spaces(macro search spaces)中,用来表示相同地Operation/Primitive,当然也可以代指一些非常出名地运算单元(比如inverted bottleneck residual layer)
- Block/Module: 模块,代指几个层串联起来的串联结构。同样常出现在链式结构或者macro search spaces中。
- Cell: 单元/元胞/
细胞?表征一个DAG拓扑的一系列Operations,通常出现在Cell-based Search Spaces。通常会指定cell中operations的个数。 - Motif: 模体/基序
(没办法我只在生化教材看过这种词),网络结构中多种Operations中存在的几个子范式(相似之处)。有的文献也认为Cell是一种高层次的Motif。
2. Macro Search Spaces 宏搜索空间
此术语包含两层含义:
-
在一个层级中对整个架构进行编码的搜索空间(特别说明;这不同于cell-based 或者 hierarchical search spaces);
解释:整个网络架构被当做一个DAG处理,NAS算法可以对DAG的每个节点进行操作,也可以对DAG的拓扑结构操作。Eg:NASBOT CNN Search Space -
只关注宏级超参数的搜索空间(
读不懂);解释:宏基超参数包括在整个架构中对空间分辨率进行下采样的位置和程度(where and how),同时保持架构拓扑和操作固定不变Eg:EfficientNet
 wechat
wechat- alipay